モーニング娘。'21画像診断 Webアプリ作成
はじめに
こんにちは! 機械学習(画像認識)を学んだので、備忘録として書きます。
今回は『モーニング娘。'21』のメンバーを判定してくれるWEBアプリを作りました。 (本当はハロプロの中から判定できるアプリが作りたかったが画像集めと下処理が大変なので断念。。。)
下記が今回作ったWebアプリです。
morningmusume21-app.herokuapp.com
仕事終わりや土日にちょこちょこやってたので、作るのに1ヶ月かかりました。
目次
ファイル構成
morningmusume_app -╷- Original -╷- 譜久村聖(分類1) -╷- 000001.jag #DLした画像
╎ ╎ ╎- 000002.jag ・・省略
╎ ╎
╎ ╎- 生田衣梨奈(分類2) - (略)
╎
╎- Face -╷- 譜久村聖_face(分類1) -╷- cutted1.jag #切り抜いた画像
╎ ╎ ╎- cutted2.jag・・省略
╎
╎- FaceEdited -╷- 譜久村聖(分類1) -╷- 0_-10.jag #水増し画像
╎ ╎ ╎- 0_-10filter.jag・・省略
╎
╎- test -╷- 譜久村聖(分類1) -╷- 3_-10.jag #テスト画像
╎ ╎ ╎- 6_10filter.jag・・省略
╎
╎- scraping_icrawler.py (スクレイピング)
╎- face_trimming.py (顔をトリミング)
╎- inflated.py (水増し)
╎- data_partitioning.py (データを分ける)
╎- model_make.py (学習)
1.スクレイピング
まずは学習に必要な大量の画像を集めます。 数千枚を1枚1枚ダウンロードするのは、pythonさんに集めてもらいます。 Aidemyでは『Beautiful Soup』を使ったスクレイピングを学びました。 スクレイピングで調べていいると、もっと簡単なやり方を発見したので、その方法でやりたいと思います。
その名は ”icrawler” です。
# 画像収集
from icrawler.builtin import BingImageCrawler
name_list = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"] #集めるアーティストの名前のリスト
for name in name_list:
crawler = BingImageCrawler(storage={"root_dir": name})
crawler.crawl(keyword = name, max_num=200) # max_num:集める画像の枚数
上記のコードを実行すると大量の画像が各メンバーの名前のファイルが作成され保存されます。 さあ、ここから大変な所!!
本人じゃない画像や他のメンバーと映ってるいる画像を取り除きます。
2.顔の切り抜き
集めた画像の顔部分だけ切り抜きます。 OpenCVの”Haar-Cascade”(カスケード型識別器)を使って切り抜きます。 識別器は様々種類がありますが、今回は正面の顔を識別する”haarcascade_frontalface_alt2.xml”を使用
import cv2
import numpy as np
import os
import os.path
# OpenCVのデフォルトの分類器
cascade_path = '/morningmusume_app/OpenCV/haarcascade_frontalface_alt2.xml' #プルパスで書いた方が良い
faceCascade = cv2.CascadeClassifier(cascade_path)
SearchName = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"]
for name in SearchName:
# 画像データのあるディレクトリ
input_data_path = '/morningmusume_app/Original/"+str(name)'#プルパスで
print(input_data_path)
# 切り抜いた画像の保存先ディレクトリを作成
os.makedirs("./Face/"+str(name)+"_face", exist_ok=True)
save_path = "./Face/"+str(name)+"_face/"
# 収集した画像の枚数(任意で変更)
image_count = 260
# 顔検知に成功した数(デフォルトで0を指定)
face_detect_count = 0
print("{}の顔を検出し切り取りを開始します。".format(name))
# 集めた画像データから顔が検知されたら、切り取り、保存する。
for i in range(image_count):
picture_name = input_data_path + '/'+ str('{:0>6}'.format(i+1)) + '.jpg'
print(picture_name)
img = cv2.imread(picture_name, cv2.IMREAD_COLOR)
print(img)
if img is None:
print('image' + str('{:0>6}'.format(i+1)) + ':NoFace1')
else:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face = faceCascade.detectMultiScale(gray, 1.1, 3)
if len(face) > 0:
for rect in face:
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.imwrite(save_path + 'cutted' + str(face_detect_count) + '.jpg',img[y:y+h, x:x+w])
face_detect_count = face_detect_count + 1
else:
print('image' + str('{:0>6}'.format(i+1)) + ':NoFace0')
print("顔画像の切り取り作業、正常に動作しました。")
生田様の画像が178枚あったのが、トリミング後78枚まで激減してしまいました。。 おそらくアイドルの自撮りでみられる斜め撮りが顔を認識出来なかったのかな?!
逆に成功率が良かったのは、小田さくらさんは、149枚がトリミング後118枚でした。
面白かったのが、山﨑愛生ちゃんです。
愛生ちゃんはパンダさんが好き有名です。
パンダさんと映っている写真が多く、こんな感じにパンダさんの顔がかなりの数、トリミングされていました。
確かに顔だが、、笑
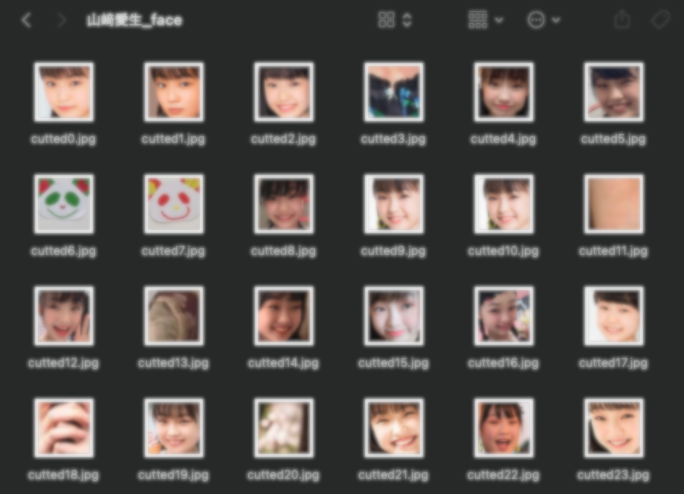
ここでも顔以外の画像をとり除きます。
3.画像の水増し
各メンバー100枚〜150枚しか集まらなかったので、画像を回したり、ぼかしたり、反転したり、ラジバンダリー。 何とか1500枚くらい集まりました。
次は ”OpenCV” を使います
import os
import cv2
import glob
from scipy import ndimage
SearchName = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"]
img_size=(250,250)
for name in SearchName:
print("{}の写真を増やします。".format(name))
in_dir = "./Face/"+name+"_face/*"
out_dir = "./FaceEdited/"+name
os.makedirs(out_dir, exist_ok=True)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./Face/"+name+"_face/")
for i in range(len(in_jpg)):
#print(str(in_jpg[i]))
img = cv2.imread(str(in_jpg[i]))
img = cv2.resize(img,img_size)
# 回転(顔が傾いてる可能性がある為)
for ang in [-10,0,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,img_size)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
#画像の左右反転
img_inve = cv2.flip(img_rot, 1)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"inve.jpg")
cv2.imwrite(str(fileName),img_inve)
# 閾値
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
# ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
#モザイク
img_mosaic = cv2.resize(cv2.resize(img_rot, (img_size[1] // 5, img_size[0] // 5)),(img_size[1], img_size[0]))
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"mosaic.jpg")
cv2.imwrite(str(fileName),img_filter)
print("{}の写真を水増し完了。".format(name))
print("画像の水増しに成功しました!")
ここは特に何にもないので、次!!!!
4.学習用とテスト用でデータを分ける
各メンバーの写真の2割をテストデータに移行します。
# 2割をテストデータに移行
import shutil
import random
import glob
import os
SearchName = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"]
for name in SearchName:
in_dir = "./FaceEdited/"+name+"/*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./FaceEdited/"+name+"/")
#img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_jpg)
os.makedirs('./test/' + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "./test/"+name)
これで画像の下処理は完了です。
5.モデルの構築〜評価
いよいよ、学習のフェーズです。 今回はVGG16を使って、転移学習をします。 自分のPCで学習すると何時間かかるか分からないので、 ”GoogleColaboratory”のGPUを使って学習させます。
まず先程作った学習用とテスト用の画像データを”Google Drive”に保存します。
import os
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras import optimizers
from keras.layers import Activation, Dense, Flatten, Input
from keras.utils.np_utils import to_categorical
import numpy as np
import time
import matplotlib.pyplot as plt
import cv2
# 分類するクラス
names = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"]
# 教師データのラベル付け
X_train = []
Y_train = []
for i in range(len(names)):
img_file_name_list=os.listdir('/content/FaceEdited/'+names[i])
for j in range(0,len(img_file_name_list)-1):
n=os.path.join('/content/FaceEdited/'+names[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_train.append(img)
Y_train.append(i)
# テストデータのラベル付け
X_test = []
Y_test = []
for i in range(len(names)):
img_file_name_list=os.listdir('/content/test/'+names[i])
for j in range(0,len(img_file_name_list)-1):
n=os.path.join('/content/test/'+names[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_test.append(img)
Y_test.append(i)
X_train=np.array(X_train)
X_test=np.array(X_test)
y_train = to_categorical(Y_train)
y_test = to_categorical(Y_test)
#input_tensorの定義
input_tensor = Input(shape=(250, 250, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dense(14, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 15層目までの重みを固定
for layer in model.layers[:15]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
history = model.fit(X_train, y_train,batch_size=32, epochs=50, verbose=1,\
validation_data=(X_test, y_test),\
)
model.summary()
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
実行結果は、下記の感じです。 まずまずですね!!

6.Herokuにデプロイ
ファイル構成
morning_app -╷- main.py
╎- model.h5
╎- Procfile
╎- requirements.txt
╎- runtime.txt
╎- templates -╷-index.html
╎ ╵-result.html
╵- static -╷- stylesheet.css
╵-result_css.css
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["譜久村聖","生田衣梨奈","石田亜佑美","佐藤優樹","小田さくら","野中美希","牧野真莉愛","羽賀朱音","加賀楓","横山玲奈","森戸知沙希","北川莉央","岡村ほまれ","山﨑愛生"]
image_size = 250
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = img.convert('RGB')
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
print(result)
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("result.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
上記の構成でデプロイしたら、早速エラーが出てしまいました。
slug sizeが大きいみたいです。
解決策を調べていると、見つかりました。 requirements.txtのtensorflowが容量を圧迫しているみたいです。 下記の参考の対策をしたら、”Done: 353.7M”になりました。
完成。 こんなwebアプリが出来ました。

まとめ
はじめは画像認識とか難しそうって思ってたけど、ライブラリがたくさん用意されていたので なんとかwebアプリを完成させることが出来ました。